One of the most overlooked aspects of DITA conversion is including metadata in your conversion project. Metadata is a powerful tool. Please, leverage it! (Go ahead and picture me shouting this from the rooftops.)
Your goal is to capture and transfer metadata that is important to your content and your processes. You want to do this for a few reasons:
- So that it’s not forgotten and left behind. “When was this content last updated and who updated it?” You don’t want the answer to be: “Who knows. We converted it last week.”
- So you can leverage your XML. Adding metadata to XML is like putting a steering wheel on your car—it gives you all sorts of control over it.
- So you don’t have to apply metadata manually after conversion, a painful and time-consuming exercise.
You can also treat your conversion project as an opportunity to introduce new metadata into your content that can really enhance its value. The moment when content is being converted to XML but is not yet loaded into a CMS is the perfect moment for adding metadata.
Part of your overall content strategy should include a section on metadata strategy, where you plan what kinds of information you want to capture (or introduce) and how you will do so.
Metadata explained
Metadata is simply information about information. The date stamp on a file, for example, is metadata about that file. Although we’re used to seeing all sorts of metadata, we rarely use it to our benefit other than by sorting a list of files. Using Windows 7, you could, for example, easily return a list of all graphics that you’ve ever uploaded to your computer that were taken with a specific lens length, no matter where they are stored. You could do the equivalent exercise with your content files (Word documents, FrameMaker files, Excel spreadsheets, etc.) if you took the time to tag them with simple category metadata.
In the context of DITA topics and maps, metadata is information that is not part of the content itself. Metadata is expressed in an element’s attributes and values, in elements in the prolog of a topic, in the topicmeta element in maps, in various other places in maps and bookmaps, and in subject scheme maps.
Metadata in the prolog element
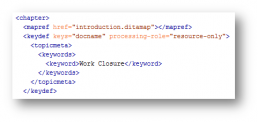
Use metadata for different purposes:
- Internal processes. For example, knowing the last date a piece of content was updated can let you know that content has become stale. This sort of metadata can also drive workflows for authoring, reviewing, and translating.
- Conditional content. Metadata is what lets you show/hide content that is specific to particular users, specific output types (like mobile), or particular products and helps you maximize your ability to single source and re-use content (thus making your ROI that much more attractive).
- To control the look and feel of your content on publish. Metadata allows information to pass to your publishing engine.
- Grouping and finding content using a taxonomy or subject scheme. Useful for both authors searching for content and end users searching and browsing for content, this strategy can be a really powerful addition to your content.
- To run metrics against. Example: Return a count of topics covering a subject matter, or the number of topics updated in the last x months by author a, b, and c. You can get metrics on any metadata you plan for and implement.
What metadata do you need to capture?
The metadata you need to capture depends on your content strategy. A good method is to start with how you’d like your users (external stakeholders) to experience their content and work backwards from there. For example, if you want localized content to display for users who are from a specific geographic location, then you need to build that in. If you want content to display differently for mobile devices, then you need to build that in.
Don’t forget about your authors when it comes to planning your metadata (it helps to think of them as internal stakeholders). Metadata can introduce some major efficiencies when planning, finding, authoring, and publishing content. A good CMS lets authors browse, search, and filter by subject matter, keyword, component, sub-component, or any other piece of metadata. Sometimes some of the metadata might be applied in the CMS itself rather than in the topics or map, so your metadata plan should include an understanding of what and how you’ll be able to leverage metadata using your CMS of choice.
However, at a minimum, think about including topic-level metadata (traditionally placed in the prolog element) that includes:
- Author
- Status of the content (for example, approved)
- Date content was originally created
- Date content was last updated
- Version of product (if applicable)
Conditional metadata
Conditional metadata is the most popular use of metadata. The conditional markers on your legacy content should be converted to attributes and their values so you can leverage profiling (publishing for specific users or output types). Not all attributes can work as profiling attributes, so make sure you do your homework when planning your metadata strategy. Also not all attributes are available on all elements.
Conditional metadata on a step element

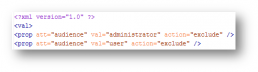
The .ditaval file goes hand in hand with conditional metadata. This is a processing file used on publish to show/hide attribute/value pairs.
Ditaval file
Publishing metadata
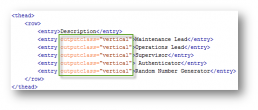
You can use metadata to control the look and feel of your content. A simple example is for table header columns that should have vertical text rather than horizontal text. A piece of metadata can let the stylesheets identify when to display text with vertical alignment.
Table with metadata that indicates some text should be vertical
Best Practices
I’m the first one to admit that managing your metadata can become a bit of a nightmare. You need to keep an eye on best practices to make sure what you implement is scalable and manageable.
When you think metadata, think map
There are no two ways about it—trying to manage metadata at the topic level is not always efficient. Instead, think about putting some metadata in maps instead. This lets you change the metadata of a topic depending on the map it is referenced in, making it more versatile.
However, there are downsides to placing metadata in maps. It means you have to duplicate effort because every time you reference the same topic, you must specify the metadata again in each map, which could lead to inconsistencies. It also means that authors can’t necessarily easily see the metadata that might be important for them to know when using or modifying the topic.
Often, some metadata at the map level lets you leverage your content intelligently while the rest should stay in the topic. Each case is unique and you should define this as part of your content strategy, but some examples are shown below.

Keep in mind that metadata that is assigned in DITA topics can be supplemented or overridden by metadata that is assigned in a DITA map, so you can overlap metadata if needed but the map is (usually) boss. For details, see the DITA specification.
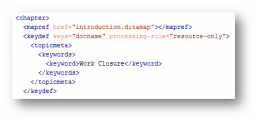
Map metadata using the topicmeta element

Keys and conkeyrefs
Some great alternatives to setting conditional or profiling attributes on elements are to use keys and conkeyrefs. These mechanisms take the control out of the topic and put it in the map or in a central location, where it belongs. When you start controlling your content from your map or from a central location, your content becomes both more versatile and more efficiently updated. For example, a topic could swap out some of its content depending on the map in which it is referenced. This can be useful for anything from a term or variable phrase to a table, graphic, or paragraph.
Use of keyref in a sentence
Defining key in map, where the keyword will replace the keyref in the paragraph above
Taxonomy/Subject Scheme
Using the subject scheme map, you can take your metadata to a whole new level. The subject scheme map is a way of introducing hierarchy into your classification or subject scheme, and then being able to leverage that hierarchy intelligently on publish. For example, you can create a subject scheme that defines two types of subjects: hardware and software. Each of these categories would be broken out into sub-categories. So hardware might include headsets, screens, and power cords. By connecting this hierarchical categorization to the topics and maps that hold your content, you can manipulate content at the lower level of categorization (for example, exclude all headsets content) or at the higher level (exclude all hardware content). It also lets you change the user experience of content for end users, so they can easily search through or browse these categories. And that’s just the beginning of what you can do with subject scheme maps.
For more information on subject scheme maps, see Joe Gelb’s presentation on this subject. Although he distinguishes metadata from taxonomy, this is really an arbitrary distinction. Think of taxonomy as a particular kind of metadata with a specific purpose.
Like any metadata effort, planning your taxonomy and subject scheme is essential. For example, identifying all installation content is probably not going to be useful to end users (who wants to see the installation topics for 40 products?) but grouping content by subcomponent could be essential. The trick is to determine what will be useful.